ACL 2023 findings paper - LEDA: a Large-Organization Email-Based Decision-Dialogue-Act Analysis Dataset
by Mladen Karan • Friday 2 June 2023 • PermalinkWe have published a new paper in the Findings of the ACL!
Intro
Collaboration increasingly happens online. This is especially true for large groups working on global tasks, with collaborators all around the world. The size and distributed nature of such groups make decision-making challenging. In our new paper we propose a set of dialog acts for the study of decision-making mechanisms in such groups, and provide a new annotated dataset based on real-world data from the Internet Engineering Task Force (IETF). We also provide some interesting results of an initial exploratory data analysisAnnotation
After experimenting with many variants of the label taxonomy in collaboration with annotators who were trained linguists we converged to the set of dialogue-act (DA) labels given in the table below: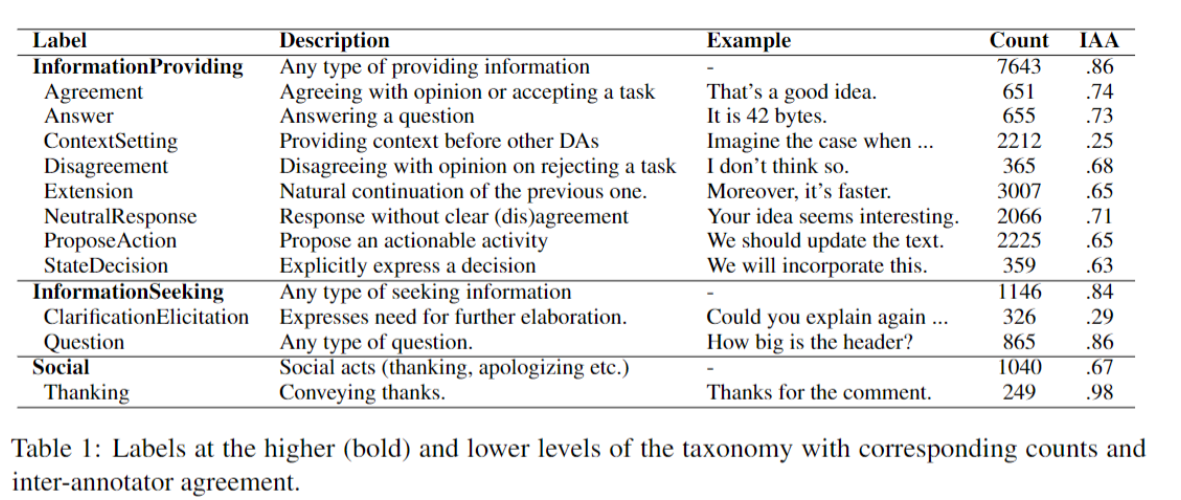
Experiments
We divided the lifecycle of the draft into five periods (T1 … T5). Below we give the distribution of each dialogue act across the periods.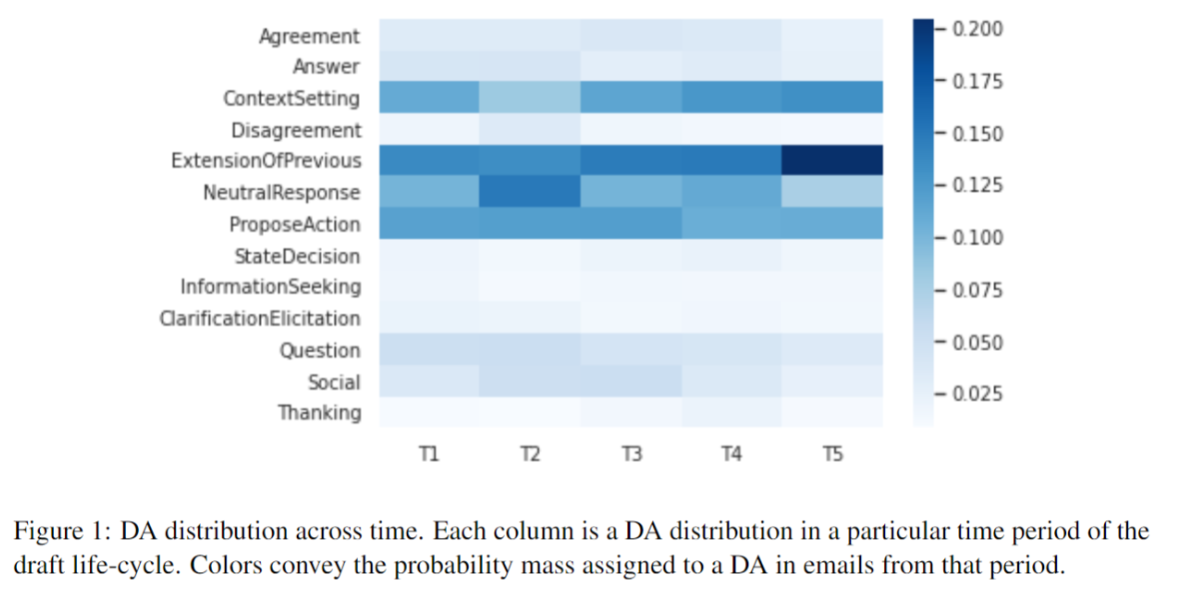
We then divided the participants in terms of their role within the organisation – draft authors, working group chairs, and influencers (participants with high centrality in the email communication network).
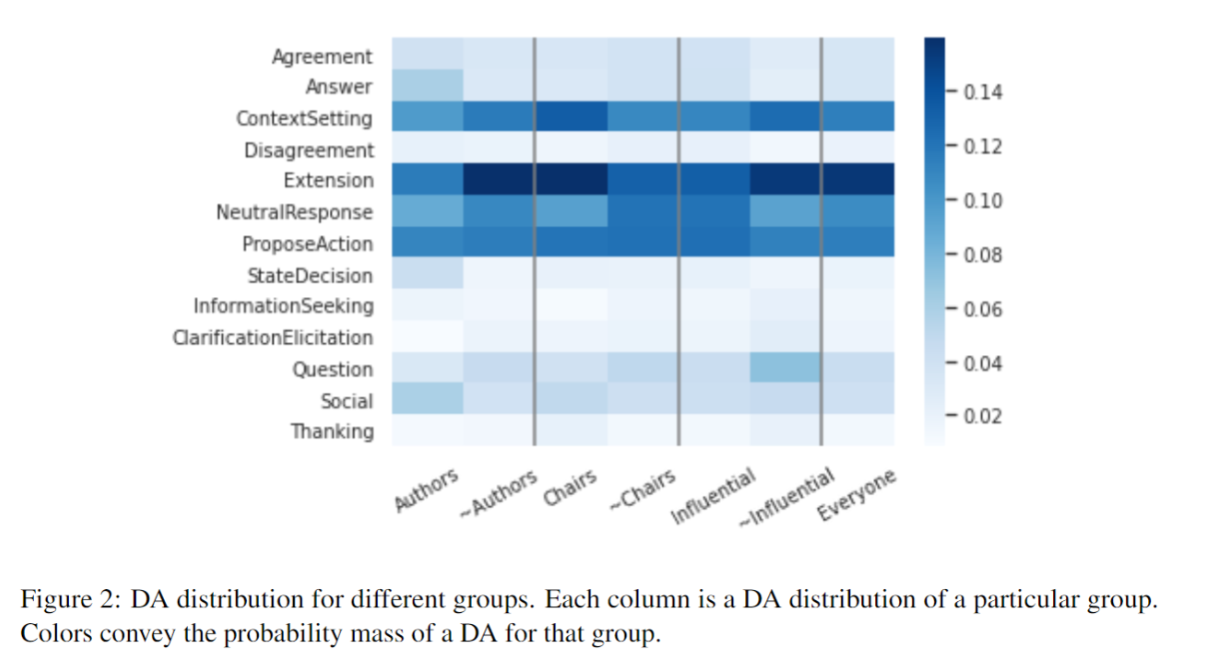
Influential vs. non-Influential Influential people use Answer, Agreement, and NeutralResponse more, making them generally more responsive. They use less Extension, ContextSetting and Thanking, implying a concise, focused communication style. As expected, they make more decisions and propose slightly more actions.
Chairs vs. non-Chairs Similar to influential participants, chairs use NeutralResponse more than non-Chairs. However, they use more ContextSetting and Extension, and do more Thanking. We find this is because chairs send a lot of emails initiating and managing discussions and review assignments. Such emails are often composed of many small segments and contain a lot of these labels.
Prediction model
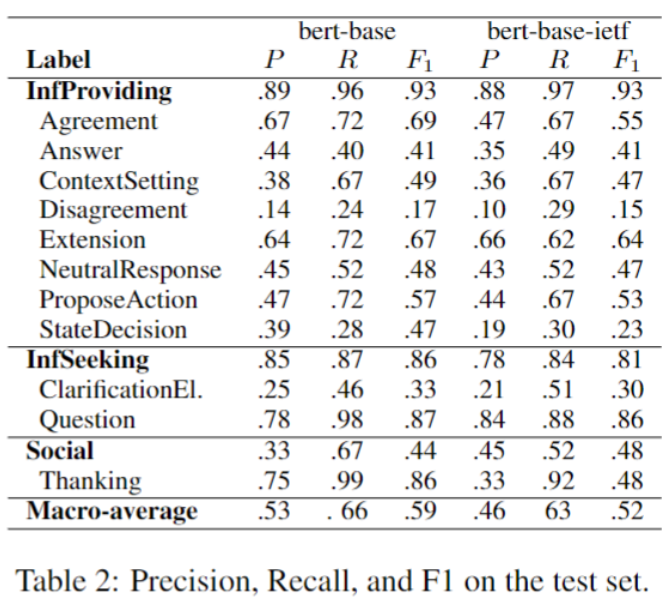
Finally, we made a BERT based prediction model for these DAs, which can serve as a baseline for more advanced models in future work. Results are given in the table below.